1 – یادگیری ماشین در پایتون

یادگیری ماشین
یادگیری ماشین به معنای واداشتن رایانه به یادگیری از طریق مطالعه دادهها و آمار است. یادگیری ماشین گامی در جهت هوش مصنوعی (AI) محسوب میشود. یادگیری ماشین برنامهای است که دادهها را تجزیه و تحلیل میکند و یاد میگیرد که نتیجه را پیشبینی کند.
از کجا شروع کنیم؟
در این آموزش از آموزشگاه برنامهنویسی و رباتیک لمپا بابل، به مباحث ریاضی بازمیگردیم و به مطالعه آمار و نحوه محاسبه اعداد مهم بر اساس مجموعه دادهها میپردازیم. همچنین یاد میگیریم که چگونه از ماژولهای مختلف پایتون برای دستیابی به پاسخهای مورد نیاز استفاده کنیم. علاوه بر این، نحوه ایجاد توابعی را که قادر به پیشبینی نتیجه بر اساس آنچه آموختهایم هستند، یاد خواهیم گرفت.
مجموعه داده
در ذهن یک رایانه، مجموعه داده به هر نوع مجموعهای از دادهها اطلاق میشود. این دادهها میتوانند از یک آرایه ساده تا یک پایگاه داده کامل باشند.
مثال یک آرایه:
[99, 86, 87, 88, 111, 86, 103, 87, 94, 78, 77, 85, 86]
مثال یک پایگاه داده:
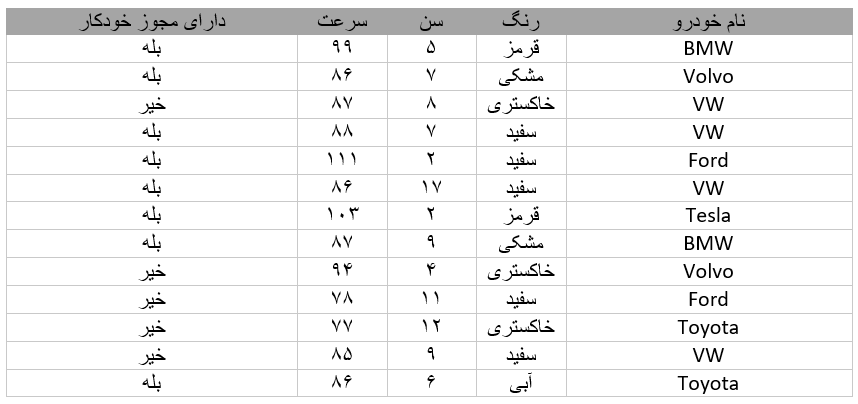
با نگاه کردن به آرایه، میتوانیم حدس بزنیم که مقدار میانگین احتمالاً حدود ۸۰ یا ۹۰ است و همچنین میتوانیم بالاترین و پایینترین مقدار را تعیین کنیم، اما چه کارهای دیگری میتوان انجام داد؟
همچنین با مشاهده پایگاه داده میتوان دریافت که رنگ سفید پرطرفدارترین رنگ است و قدیمیترین خودرو ۱۷ سال سن دارد. اما اگر بتوانیم تنها با مشاهده سایر مقادیر، پیشبینی کنیم که آیا یک خودرو دارای مجوز خودکار است یا نه، چه میشود؟
این همان کاری است که یادگیری ماشین انجام میدهد! تحلیل دادهها و پیشبینی نتایج!
در یادگیری ماشین، معمولاً با مجموعه دادههای بسیار بزرگ کار میشود. در این آموزش، سعی میکنیم مفاهیم مختلف یادگیری ماشین را به سادهترین شکل ممکن توضیح دهیم و با مجموعه دادههای کوچک و قابلفهم کار کنیم.
انواع دادهها
برای تحلیل دادهها، مهم است که بدانیم با چه نوع دادهای سروکار داریم. میتوان دادهها را به سه دسته اصلی تقسیم کرد:
– عددی (Numerical)
– دستهای (Categorical)
– ترتیبی (Ordinal)
دادههای عددی (Numerical Data) شامل اعداد هستند و خود به دو دسته تقسیم میشوند:
1- دادههای گسسته (Discrete Data)
دادههایی که شمارششدنی هستند و تنها به مقادیر صحیح محدود میشوند. مثل تعداد خودروهایی که از یک خیابان عبور میکنند.
2- دادههای پیوسته (Continuous Data)
دادههایی که اندازهگیریشدنی هستند و میتوانند هر مقدار عددی داشته باشند. مثل قیمت یک کالا یا اندازه یک شیء.
دادههای دستهای (Categorical Data) دارای مقادیری هستند که قابل اندازهگیری در برابر یکدیگر نیستند. مثل مقدار رنگ یک خودرو (قرمز، آبی، سفید) یا مقدارهایی که پاسخ آنها بله/خیر است.
دادههای ترتیبی (Ordinal Data) شبیه دادههای دستهای هستند، اما میتوان آنها را در برابر یکدیگر سنجید و مرتب کرد. مثل نمرات مدرسه که در آن نمره A بهتر از نمره B است و همینطور ادامه دارد.
با دانستن نوع دادههای موجود در منبع داده خود، میتوان تصمیم گرفت که از چه تکنیکی برای تحلیل آنها استفاده کنیم.
در بخش های بعدی و با دنبال کردن آموزشگاه برنامه نویسی بابل، آموزشگاه لمپا، مطالب بیشتری درباره آمار و تحلیل دادهها خواهیم آموخت.

0 دیدگاه